Last Friday, we introduced the PAPI Staking Optimizer, the most performant staking dashboard to date.
This release is the culmination of an effort that originated from building the PAPI Staking SDK, similar to how we built the PAPI Bounty Manager using the Governance SDK.
In addition, we’ve abstracted the account management used across our dApps into a new modular library, PolkaHub, making it effortless to integrate with any Polkadot wallet. It’s also the first library to support the air-gapped Polkadot Vault out of the box!
I wanted to create a post explaining the SDKs, the main points of the Staking Optimizer, and a quick overview of PolkaHub’s core principles.
PAPI SDKs
The Polkadot-API library is designed to be modular and chain-agnostic, meaning it does not include any business-level logic. It reads the chain metadata to understand how to interact with the chain, but it’s up to the developer to define its specific use and purpose.
With this modular architecture, it becomes possible to build additional libraries on top that simplify common workflows when dealing with specific pallets. So far, we’ve built the following SDKs, highlighting their most important features:
-
Identity: Decodes identity information and resolves sub-identities.
-
Linked Accounts: Explores proxy and multisig relationships between accounts.
-
Bounties: Simplifies access to bounty information and finds linked referenda.
-
Referenda: Calculates support curves and optimizes referendum creation.
-
Voting: Abstracts voting information and calculates locks.
-
Ink!: Handles smart contracts with
pallet-contractsandpallet-revive, supporting both ink! and Solidity ABIs. -
Multisig: Creates multisig transactions based on the current state.
-
Remote Proxy: Creates remote proxy calls.
-
Statement: Simplifies access to the statement store.
Now we’ve added the Staking SDK. When interacting with the staking pallet, relevant information such as validator status, nominator settings and rewards is typically scattered across different storage entries. This SDK aggregates everything, making it much easier to consume.
For example, getting the bond of a nomination pool member is not straightforward. It’s not stored directly as an amount of tokens in the pallet’s storage but as points, a mechanism that determines how a slashing event affects the members in a nomination pool. This makes it non-trivial to retrieve a member’s bond, as those points have to be transformed to tokens.
Additionally, the SDK provides utilities to manage nomination status. Any nomination change can be performed with a single batch transaction, and it also helps optimize bond amounts by rebonding previous locks when possible.
As you can see, this suite of libraries enhances specific blockchain features while preserving the modular philosophy. We also encourage other teams to build their own SDKs. For example, the Statement Store SDK actually originated from an external team, the ParaSpell team also developed an XCM SDK, Hydration built the Galactic SDK, etc.
Staking Optimizer
To build the right abstraction, we need a real use-case example. When developing the Governance SDK (bounties, referenda, and voting), we built Polkadot Bounties. Similarly, for the Staking SDK, we created the Staking Optimizer.
These are what we call our white-label dApps: They help us test and refine the SDKs while also serving as examples or even potential starting points for anyone who wants to fork and improve them.
The Staking Optimizer has been used to battle-test the SDK, with a focus on a few key points:
-
Making it light-client first.
-
Displaying the important validator metrics.
-
Keeping it highly performant.
Light-Client First
We believe in a fully decentralized network. There’s still work to be done to reach that ambitious goal, but building dApps that prioritize decentralization is key to push the ecosystem in the right direction.
Polkadot’s light client, Smoldot, is an impressive piece of engineering. It can fully synchronize with the chain to the latest finalized block in less than 10 seconds, and in a completely trustless manner. This is extremely important: not only is it unstoppable, but any information you retrieve from Smoldot is fully verified.
The Staking Optimizer was built with Smoldot in mind from the ground up. It includes several performance optimizations that make it run smoothly, achieving more than acceptable performance levels.
We’ve also added support for centralized RPCs and a small open-source indexer to offload some heavy operations. However, these are optional enhancements intended only to make things slightly faster. At any time, users can switch back to the fully trustless and decentralized option using Smoldot.
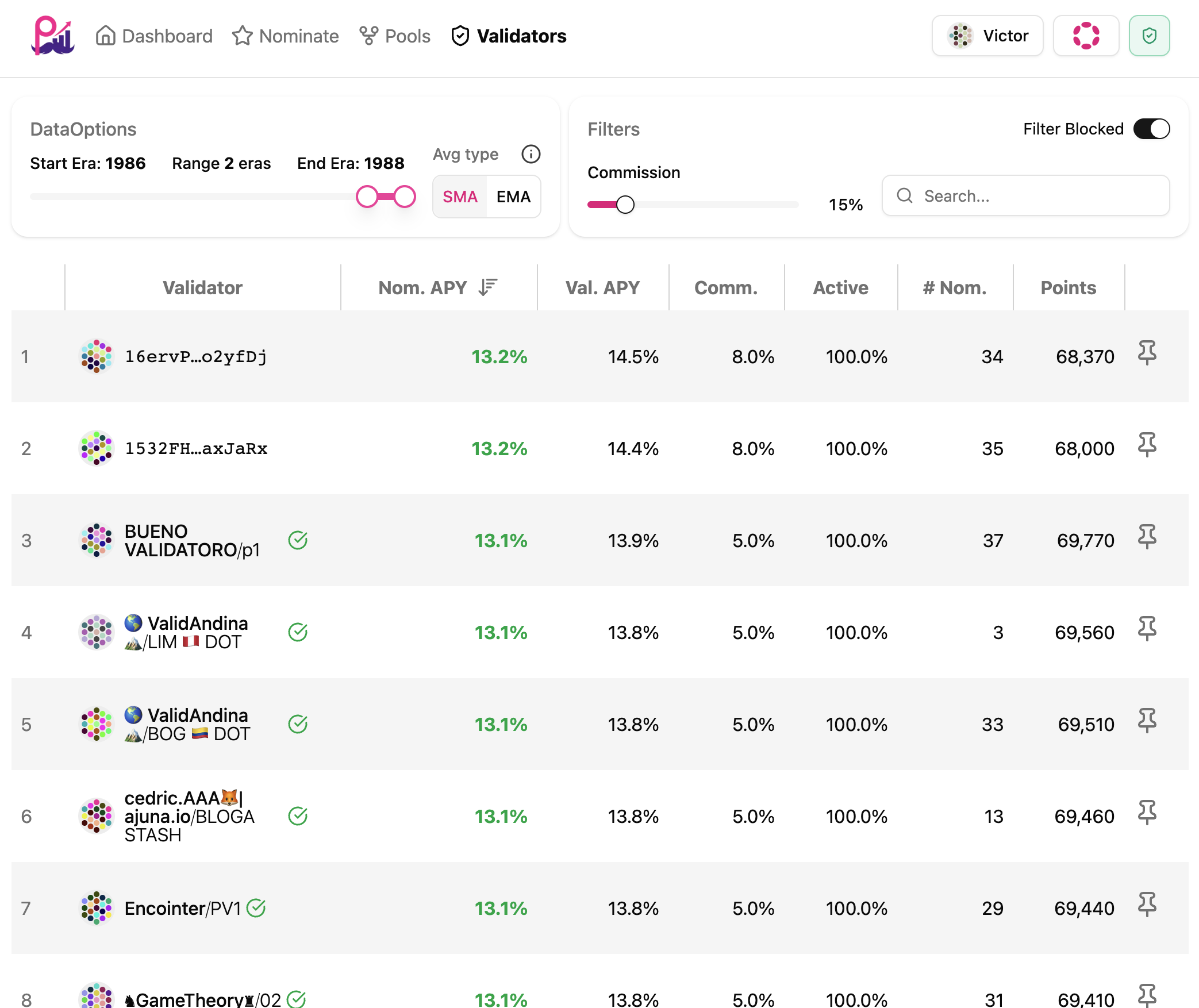
Validator Metrics
What defines the performance of a validator? From an investment perspective, what matters is the amount of rewards you receive relative to the tokens you have locked. In other words, the APY (Annual Percentage Yield).
In staking, active validators earn points as they produce blocks. At the end of each era, a total reward is determined (based on inflation curves and current issuance), and that reward is distributed among validators in proportion to the points they’ve earned.
Each validator’s reward is then shared with its active nominators. First, the validator takes their commission (according to their commission setting), and the remaining amount is split proportionally based on each nominator’s active stake (including the validator’s if they have self-stake).
From this description, it might seem that a validator APY’s performance depends mainly on the number of points earned and its commission rate, since these directly affect the total rewards shared with nominators. However, that’s not actually the full picture.
If you look at the data, validator points are quite similar across the active set. Validators with more stake tend to earn slightly more points, but the difference is marginal compared to the total amount of tokens. When thinking in terms of APY, how much return you get per token, it’s usually better to nominate validators with less total stake.
This is why you might find a validator with 10% commission yielding a higher APY than another with 0% commission: the 0% validator often has too many tokens bonded, which dilutes its yield.
If every nominator based their decision purely on APY, the system would naturally self-balance: validators with higher APY would attract more nominators until their performance evens out, and the other way around.
Another interesting aspect is blocked nominations. Validators can configure a setting to block new nominations. If you disable the Block nominations filter, you’ll often see that the top-performing validators are blocked. And for good reason, as they prefer not to take additional stake from unknown nominators that would in turn decrease their APY.
Related to this, a few months ago, joining a nomination pool could yield a higher APY than directly nominating, even with double commission (validator + pool). This was because those pools were nominating blocked validators that happened to have the highest APY.
This APY-based performance metric is what the Staking Optimizer focuses on displaying clearly. It’s unclear what metric the other Staking Dashboard uses (since it relies on its own indexer which is closed-source), it just shows validators with a “Top 10%” tag, and the charts are based on points or total rewards. This is something we aimed to improve upon.
We also plan to add more important metrics in the future, such as decentralization, to help users make even more informed validator selections.
Sorry if this section got a bit long, but these findings were too interesting not to share.
Performance
There are two distinct sides of performance: startup performance (getting the application to run as quickly as possible) and runtime performance (making the application feel responsive and smooth).
For startup performance, the most important concept is the critical path: all the steps that must happen in sequence before the application becomes usable.
Ideally, you want to minimize the amount of data that needs to be downloaded, including the code itself: HTML, JS, and CSS. One common way to achieve this is server-side rendering, where a server generates the application and ships it with a minimal JavaScript runtime. However, in our case, that approach is off the table since it goes against decentralization principles.
Instead, we focused on reducing the amount of code that needs to be downloaded using code splitting. The idea is to keep a minimal “main bundle” containing only the essential code needed to get the app running, while additional code (such as other pages, animations, and extra features) loads in the background as the user interacts with the app.
PAPI helps with this. Its code generation system, which ensures runtime safety, condenses the chain metadata into a small bundle that’s lazy-loaded in the background, so it doesn’t increase the main bundle size.
We can examine the bundles used by the Staking Optimizer:

As you can see, the main bundle (top-left corner) is roughly 20% of the total size. And looking closer, most of that main bundle is made up of dependencies needed to render a typical React app: about 36% of the main bundle is React and React Router alone. There are still a few pages that could be further optimized, but at some point, the trade-off isn’t worth it: saving ~5 KB often adds unnecessary complexity.
This is what lets the application load as fast as possible, to let the light client start connecting to peers as the rest of the non-essential assets are loaded in the background.
As for runtime performance, following general best practices (avoiding unnecessary re-renders, using smart caching, etc.) is usually sufficient. For certain operations, such as fetching nominator rewards, a large amount of data needs to be processed. For those cases, we use a web worker, which offloads computation to a separate thread to avoid blocking the main UI. This optimization is specific but very effective for that heavy workload.
PolkaHub
With this new dApp, we’ve also extracted our wallet integration into a standalone library called PolkaHub, built from everything we’ve learned so far. It integrates with multiple providers, including browser extensions, Ledger, and Polkadot Vault, and also supports other account types such as read-only accounts, multisigs, and proxies.
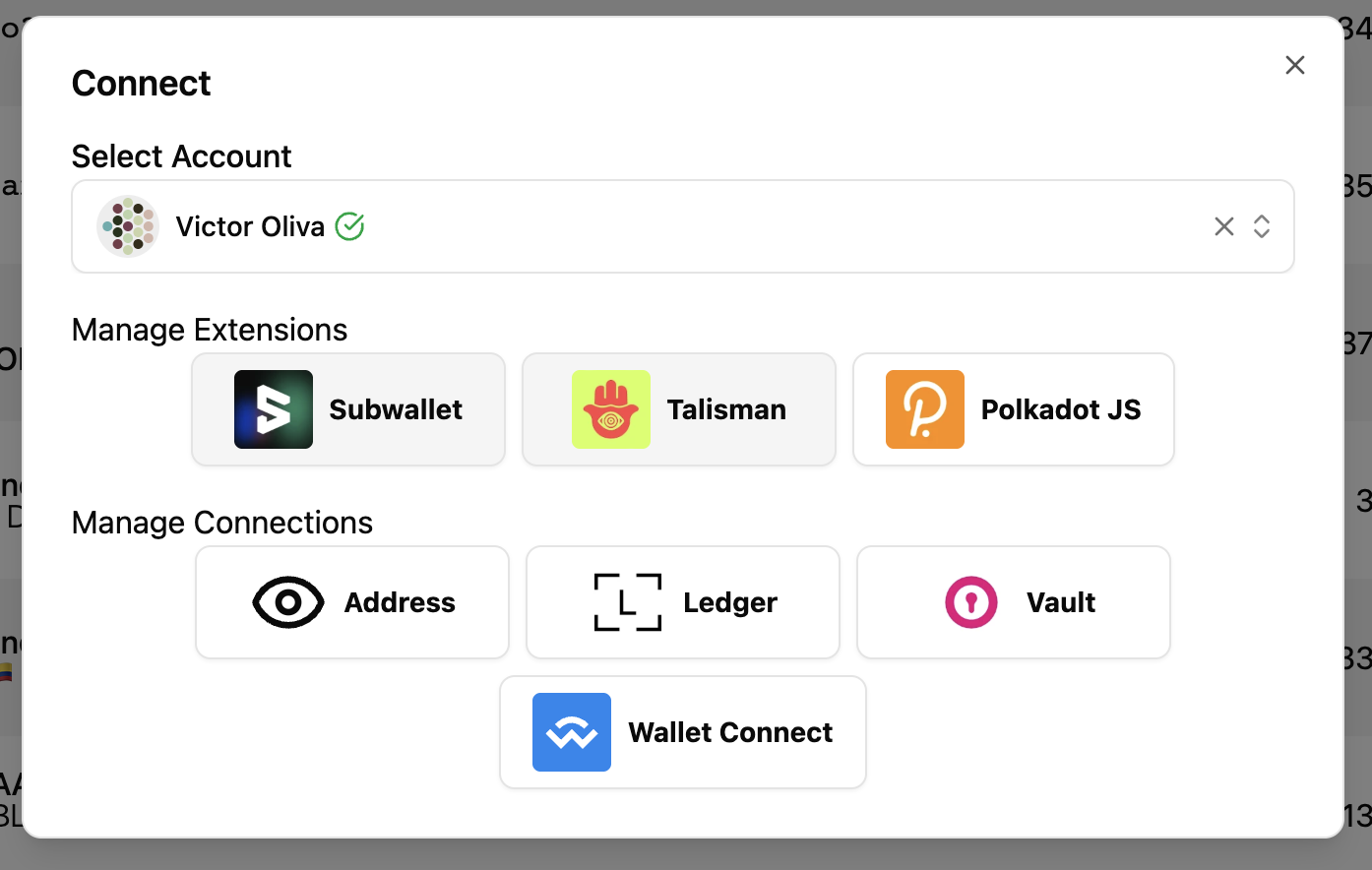
We wanted this library to serve the entire ecosystem, so it’s not tied to any specific Polkadot client library: you can use it with whichever setup suits you best.
PolkaHub is designed to be extremely modular. The core library is empty by default, and you can extend it by adding providers through a plug-in system to fit your needs. The state and integration logic are completely decoupled from the UI, allowing you to build your own interface on top without worrying about implementation details, like how Ledger connections work, for example.
For faster development, it also includes a set of predefined React + shadcn/ui components and hooks, so you can have a working integration up and running within minutes.
What’s Next
We have a busy end-of-year schedule ahead. We’re on track to deliver the remaining parts of our PAPI proposal. A v2 release is just around the corner, introducing a few minimal but much-needed breaking changes to improve the API.
As for future improvements on this project, we’re looking for feedback for the Staking SDK as it gains adoption. For the Staking Optimizer, we plan to add more validator metrics and possibly integrate the W3F validator picker based on Jonas’ research. For PolkaHub, we’ll focus on improving proxy and multisig support, and work on further standardizing the signer interface.
Stake your tokens at staking.usepapi.app and let us know what you think, we’re completely open to feedback. We hope this post was informative.