Hi! ![]()
This entire concept was imagined based on my own ideas, with the help of artificial intelligence to structure and deepen certain technical reflections. My intention here is not to propose a definitive solution, but rather to invite everyone to open their minds and reflect together on the possibilities offered by JamChain and the new horizons that such a decentralized architecture could open for artificial intelligence and beyond.
From a technical perspective, it is important to emphasize that the approach I propose with the integration of JamChain far exceeds the ambitions and capabilities of current projects like Ethernal AI or Bittensor. While these projects are innovative, they lack both the scalability and flexibility needed to efficiently manage massive artificial intelligence models in a decentralized way. With JamChain, we are entering a new era where cryptographic security, resource optimization, and distributed management allow us to overcome these challenges, offering a technically viable, relevant, and disruptive solution for decentralized AI.
Technical challenge: Why JamChain is necessary for decentralized AI
Current blockchains, even those like Ethereum after its transition to Proof of Stake, are not capable of effectively supporting the massive computational loads required by a large-scale decentralized artificial intelligence project, such as the training and inference of large language models (LLM). Here are the major limitations and why JamChain presents itself as the ideal solution.
- Limited Scalability of Current Blockchains
Blockchain infrastructures like Ethereum or other current smart contract systems rely on a model where each transaction must be verified and validated by all nodes in the network. This poses constraints on:
- Parallel processing: LLM models require massive parallel computations, which are often impossible to execute efficiently on blockchains where each node must process every transaction.
- Global state accumulation: On-chain data accumulates, creating bottlenecks for node synchronization and increasing latency, particularly for systems that must handle large volumes of data like an LLM model.
Even with Layer 2 solutions, reliance on a central layer for transaction finality remains a barrier to truly decentralized intensive computations.
- JamChain: An Infrastructure Optimized for Decentralized AI
In-Core / On-Chain Duality
JamChain proposes a hybrid In-Core / On-Chain approach that effectively manages heavy off-chain computations while maintaining the security and transparency of on-chain results. This approach is essential for a project based on LLM models where intensive computation and frequent model weight updates are required.
- In-Core intensive computation: Heavy operations, such as token vectorization and model weight adjustments, can be executed off-chain, in the core. This ensures optimized resource usage, reducing the load on the blockchain and increasing performance.
- On-Chain finality: Once computations are validated, the results (e.g., adjusted weights or validated inferences) are transferred on-chain, ensuring traceability and cryptographic security of critical information. This maintains transparency while reducing chain saturation.
Massive Scalability via Parachains and Asynchronous Blocks
JamChain’s architecture relies on dedicated parachains, which allow for managing different parts of the computational process in parallel. These parachains operate independently but are secured by the central relay chain, enabling horizontal scalability and reducing processing delays.
- Specialized parachains: By creating parachains specific to certain tasks (such as LLM training), we ensure that the network can grow as demand increases while distributing the computational load among nodes.
- Asynchronous blocks: The use of asynchronous blocks allows for processing multiple transactions in parallel, without waiting for each block to be fully validated before moving to the next. This significantly improves transaction throughput and reduces latency, which are crucial for real-time inferences on an LLM model.
- Advanced Security and Cryptographic Validation
JamChain offers validation mechanisms such as Proof of Validity, which ensure that every transaction or computation (including inferences and model adjustments) is cryptographically verified before being recorded on-chain. This model is perfectly suited to the demands of a decentralized AI system.
- Inference validation: Inferences submitted by PoI nodes are validated by PoC nodes before being integrated into the chain. This guarantees result quality and prevents the submission of incorrect or malicious data.
- Fast and immutable finality: Once validated, results are recorded on-chain with fast finality, ensuring that all modifications and model adjustments are traceable and transparent to all network participants.
Invitation to Reflection
This JamChain-based model could truly transform how we envision decentralized AI. The current limitations of blockchains in terms of intensive computation and scalability make it impossible to implement large-scale decentralized training and inference systems.
However, with JamChain, we have the opportunity to explore a model where the decentralization of AI is not only possible but also optimized. It is an infrastructure tailored to these needs and capable of addressing the technical challenges we face today. I invite you to reflect on the possibilities offered by JamChain for decentralized AI projects and consider how this new architecture can truly change the game in the field.
Introduction 
In a world where technological advancements increasingly shape our societies, artificial intelligence (AI) plays a central role in many sectors. However, the current centralization of AI presents significant challenges. Large companies dominating this field monopolize access to computational resources, the massive datasets required for model training, and the platforms that provide access to AI results.
This concentration of power raises critical questions: How can we make AI more accessible, transparent, and inclusive? How can we enable individuals, small businesses, and communities to have an active role in its development? Moreover, how can we create an open economy where every contributor, large or small, can benefit from the growth of this technology?
The project we are proposing positions itself as a solution to these issues. By combining the latest innovations in decentralized blockchain, distributed computing, and decentralized governance, our infrastructure aims to democratize access to AI. We enable all participants to contribute actively, whether by providing computing power, validating inferences, or submitting datasets, while being rewarded fairly through a circular economy based on the DOT token.
With a radically new approach, we believe that AI should not be the preserve of a small group of powerful actors. It must become a common good, where innovation, transparency, and inclusivity are at the heart of the process. Through a secure on-chain infrastructure, fair economic mechanisms, and participatory governance, our project embodies this vision of the future.
Problems 
Artificial intelligence, while promising, is currently dominated by a small number of large companies with the resources to train massive models. This centralization poses several major challenges that limit access to innovation and restrict participation in the evolution of AI.
- Centralization of computational power and data
The training process for AI models, especially large language models (LLMs), requires enormous amounts of computational resources. These infrastructures, often composed of data centers equipped with specialized GPUs and TPUs, are out of reach for most individuals and small organizations. This situation creates a significant gap, where only a few entities can access the tools needed to train and exploit AI at scale.
At the same time, access to the massive datasets required for model training is also centralized. Dominant companies collect and own much larger volumes of data than are accessible to the public or small organizations. This gives these players a monopoly on AI advancements, limiting innovation to a small circle of privileged actors.
- Lack of transparency and governance
The processes of training, inference, and model evaluation are often opaque. End users do not have access to the underlying data or the methods used to train the models. Moreover, it is difficult to know how inferences are generated, what biases exist in the models, or how decisions are made.
Centralized governance of these systems presents another problem. Updates, parameter adjustments, and resource management are decided by a small group of individuals without real transparency or open participation. This lack of control and participation makes it impossible to ensure the fairness and justice of decisions made by these AI systems.
- Economic barriers and limited participation
Training and using AI models are expensive. Cloud computing infrastructures charge high prices for data processing and large-scale inference execution. This limits access to artificial intelligence for small organizations and individuals, making innovation and AI research inaccessible to many.
Furthermore, there are few incentive mechanisms for individuals or small organizations to contribute to model training or provide computational power. Those with modest computational resources or specific datasets have no incentive to participate in training or developing current models, as the benefits are centralized within large companies.
- Risk of power concentration and lack of diversity
The control of AI by a few centralized companies creates a risk of excessive concentration of power. These entities not only control the models they train but also the ethical and technical decisions that affect millions of people. The lack of diversity in perspectives and contributions can exacerbate biases in AI models, limiting their fairness and ability to address the needs of a diverse society.
These challenges highlight the need for a decentralized infrastructure, where participation is open to everyone, and where each contributor can benefit from the growth of artificial intelligence. Our project aims to address these challenges by building a system that promotes transparency, accessibility, and equitable participation in the development of AI.
Project Vision
- Decentralized Architecture for the LLM Model
Our project is based on a hybrid architecture combining Proof of Inference (PoI) and Proof of Contribution (PoC), which enables decentralized training and inference for the language model (LLM). This approach ensures that every actor in the network can actively participate in the development of the model, whether by providing computational power, validating data, or contributing to governance.
Proof of Inference (PoI): Distributed computing and real-time inferences
PoI nodes play a central role in performing inferences and distributing the training of the LLM model. Each PoI node participates in the following tasks:
- Token vectorization: When a dataset is submitted or when an external user request is processed, PoI nodes begin with token vectorization. This critical step transforms textual data into numerical vectors, representing semantic relationships between words and phrases. These vectors are essential for the model to process the data effectively.
- Distributed training: PoI nodes are responsible for training specific portions of the model. By working on independent chunks of data, they generate gradients, which are then sent to the central client. The client aggregates these gradients to adjust the global weights of the model. This distributed training process ensures that the workload is shared among multiple nodes, allowing the network to scale without relying on a single actor.
- Real-time inferences: When a user submits a query to the AI, PoI nodes handle the token vectorization and the calculation of inference results in real-time. This ensures a fast and accurate response, allowing the AI infrastructure to remain responsive to increasing demand.
- Open participation: The system is designed to allow any actor with computational resources to participate. Whether using GPUs, TPUs, or CPUs, each node can contribute to model training and inference according to its capabilities. This promotes the democratization of access to AI training and reduces dependence on centralized data centers.
Proof of Contribution (PoC): Validation of inferences and decentralized governance
PoC nodes ensure the validation of inferences performed by PoI nodes and actively participate in the decentralized governance of the network. Their role is essential to guarantee the data quality and transparency in managing the model.
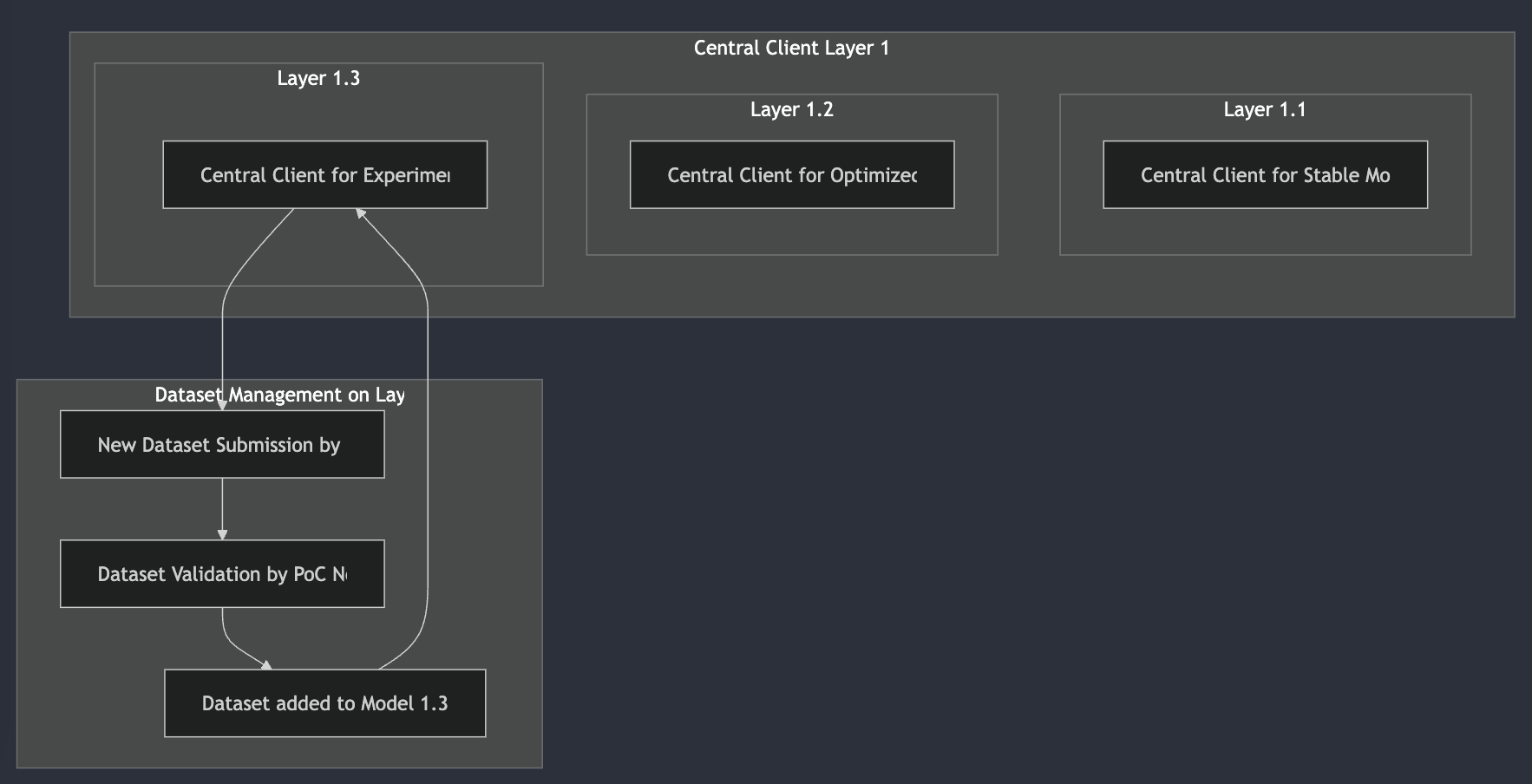
- Validation of inferences and datasets: Each inference executed by a PoI node is subject to a validation process by PoC nodes. They ensure that the results are correct and that the datasets submitted for training meet the required quality standards. This validation mechanism is crucial to maintain the integrity and reliability of the LLM model.
- Submission and validation of datasets: PoC nodes can also submit datasets for model training. Before being used, these datasets are validated by other PoC nodes, ensuring that only relevant and reliable data are integrated into the training process. This helps avoid the introduction of bias or inappropriate data.
- Participation in decentralized governance: In addition to validating inferences, PoC nodes are responsible for the governance of the network. They participate in strategic decisions, such as model updates, economic adjustments, or network improvement proposals. Each node has a voting power proportional to its contribution, ensuring that network control remains shared among participants.
2. Separation of the Original Model Training
One of the major challenges in developing an LLM model is ensuring that the original model remains intact and high-quality, while allowing it to be adapted to specific cases or specialized data.
To achieve this, we propose several mechanisms for separating the training phases:
Fine-tuning and Version Management
Fine-tuning is a process where the base model is used to train specific layers without compromising the integrity of the original model. This allows us to:
- Freeze the original model: Only certain layers of the model are adjusted, while the fundamental layers remain intact.
- Adapt the model to specific tasks: New data can be integrated to adjust the model’s parameters for specific tasks without affecting its overall capabilities.
Checkpoints and Versioning
Each phase of the model’s training is versioned through checkpoints, allowing us to clearly distinguish between different stages of the model’s evolution. These checkpoints are stored on-chain, providing complete traceability of the adjustments made to the model.
- Training from specific versions: Inferences or adjustments can be made on specific versions of the model, ensuring that the original model is never compromised during specialized training phases.
- Comparison between versions: Thanks to the checkpoints, it is possible to compare the performance of different versions of the model, ensuring that each adjustment brings a measurable improvement.
Multi-task Learning and Model Distillation
To ensure that the original model can be used in different contexts, we adopt a multi-task learning approach, where the base model is shared across several distinct tasks while maintaining the independence of the results.
- Model distillation: The results of the original model can also be used to train simpler specialized models without altering the base model. This distillation simplifies the model for specific applications while retaining the general knowledge acquired during the initial training.
3. On-Chain Infrastructure: Security and Transparency
Our project relies on a fully on-chain infrastructure to ensure maximum security, complete transparency, and efficient resource management. By leveraging JamChain, an innovative blockchain from the Polkadot ecosystem, we have designed a framework where model training operations, inference validation, and dataset management are conducted directly on-chain, without relying on external centralized solutions.
JamChain: A blockchain optimized for artificial intelligence
JamChain is designed to handle intensive on-chain computations, making it ideal for executing language models such as LLMs. PoI and PoC nodes utilize this infrastructure to perform complex computational tasks while remaining decentralized and transparent.
- On-chain computational tasks: All inferences and adjustments to model weights are performed directly on the blockchain. This ensures that every decision made by the model is traceable and can be audited at any time. This level of transparency is impossible to achieve with traditional centralized infrastructures.
- Intermittent blocks for optimal efficiency: Instead of storing all data continuously, JamChain uses intermittent blocks to integrate only critical data such as model parameters, validated datasets, and adjusted weights. This reduces the load on the chain while ensuring that essential information is stored immutably and securely.
On-chain storage of datasets and parameters
In our architecture, validated datasets and model parameters are stored on-chain. This choice ensures total transparency regarding how data is processed and used for model training. Additionally, on-chain storage guarantees the longevity of the data while minimizing the risks of manipulation or corruption of the information.
- Data security and immutability: Each validated dataset and weight adjustment is immutable once recorded in a block. This immutability protects against any unauthorized modification or attempts to manipulate the data used for model training.
- Efficient parameter management: The adjusted weights and gradients from training are also stored on-chain. This allows for complete traceability of model versions while facilitating the evolution of its performance. Each training stage is documented, providing a clear view of the model’s progression.
Transparency and traceability via JamChain
Complete decentralization of operations allows tracking of every step in the model training and inference process. The blockchain ensures that decisions and adjustments are public and accessible to any participant, ensuring unmatched transparency.
- Inference traceability: Every inference performed by PoI nodes is recorded on-chain, allowing any network participant to verify the results, the methodology used, and the adjustments made to the model.
- Model auditability: Model parameter adjustments, dataset submissions, and validations performed by PoC nodes are all audited in real-time through JamChain. This ensures that the network remains impartial and equitable, with every decision visible to all.
4. Circular Economic Model Based on the DOT Token
The project’s economic infrastructure relies on the use of the DOT token, which is central to our circular economic model. This token ensures both the rewards for contributions made by PoI and PoC nodes and allows external users to access AI services smoothly and fairly. Through this approach, we create a sustainable ecosystem where contributions are rewarded and users benefit from value-added AI services.
Rewards for Contributions
PoI and PoC nodes play a fundamental role in the network’s operation and are rewarded in DOT based on their contributions.
- Rewards for PoI nodes: PoI nodes, which provide computational power to execute inferences and train the model, are rewarded proportionally to their participation. Rewards are calculated based on computation time and the quality of results obtained during inferences and training.
- Rewards for PoC nodes: PoC nodes, which validate inferences and datasets, are also rewarded in DOT. Their role is crucial in ensuring the quality and reliability of data, and these rewards encourage active participation and high-quality contributions to the network.
Payments for AI Services
The DOT token is used by external users to access the services provided by the AI. Whether for executing inferences, accessing complex analyses, or utilizing advanced services, users pay in DOT for each interaction.
- Constant demand for DOT: By paying to access AI services, external users and businesses generate a constant demand for DOT. This drives the project’s economy, creating a virtuous cycle where users fund the network, and the nodes that contribute to its functioning are rewarded.
- Premium AI services: Businesses can access premium services (in-depth analysis, specific data processing, etc.) by paying an additional amount in DOT. This adds a level of customization while strengthening the network’s economy.
Circular Economy and Redistribution
The project’s economic model is based on a virtuous cycle of token redistribution, ensuring both economic sustainability and incentives for participation.
- Fair reward redistribution: The DOT collected from users is redistributed to PoI and PoC nodes based on their respective contributions. This model ensures that every participant in the network benefits from AI growth while maintaining a continuous incentive to actively participate.
- Sustainable ecosystem growth: By ensuring constant demand for AI services and reinvesting a portion of the DOT through buybacks, the project’s economy is designed to grow in a stable and sustainable manner. Every user, whether contributor or consumer, plays a role in driving the ecosystem’s dynamic growth.
5. Decentralized Governance and Active Participation
Decentralized governance is a central element of our project, ensuring that strategic decisions about the network are not in the hands of a small group of actors but are shared among all participants. Through an on-chain voting structure and the active participation of PoI and PoC nodes, each community member can influence the model’s future, its updates, and its economic adjustments.
On-Chain Voting Process
In our system, all important decisions regarding the network, model training, and economic management are made collectively through a fully decentralized voting process. Each participating node, whether PoI or PoC, has voting rights proportional to its contribution and can propose or vote on changes within the network.
- Participation of PoC nodes: PoC nodes play a key role in the governance process. By validating inferences and submitting datasets, they earn voting power and can influence decisions made within the network. This includes issues such as model updates, parameter adjustments, or changes in the reward structure.
- Open and transparent proposals: Every participant can propose modifications or improvements to the model or infrastructure. These proposals are then submitted to an on-chain vote via OpenGov, ensuring that all decisions are public and transparent. The result of each vote is recorded and accessible to all participants.
Transparency and Inclusion
The governance process is designed to be inclusive and ensure that every participant in the network can play an active role. Whether a PoI node contributing computing power or a PoC node validating inferences, each has the opportunity to participate in the network’s strategic decisions.
- Votes proportional to contributions: Voting rights are allocated based on the actual contribution of nodes to the network. PoI nodes that execute more inferences or computations, or PoC nodes that validate more data, see their voting power increase proportionally. This ensures that decisions are made by those who actively contribute to the network’s growth.
- Decentralized control of the model: Every aspect of the model (weight adjustments, parameter changes, or the integration of new datasets) is subject to voting, ensuring that the model remains under community control. This mechanism prevents any form of power centralization, making the network resilient and adaptable to changes.
Economic Regulation Mechanisms
Governance also plays a key role in the network’s economic management. Decisions on rewards, staking rate adjustments, or the buyback schedule are all subject to the voting process. This helps maintain economic balance and adjust the network dynamics to meet the community’s evolving needs.
- Reward adjustments: Nodes can vote to readjust the rewards allocated based on contributions. For instance, if more nodes join the network, rewards can be distributed more evenly to ensure fair compensation.
- Economic parameter modifications: Staking rates or reward caps can be adjusted to maintain the network’s economic stability and respond to fluctuations in demand for AI services.
6. Security and Scalability
The decentralized infrastructure of our project is based on robust security mechanisms and flexible scalability. The goal is to ensure that the network can grow while maintaining high security standards to protect user data, inference results, and training processes.
Data and Transaction Security
Data security is at the core of our infrastructure. Every operation, whether it involves dataset submission, inference, or parameter adjustment, is protected by an on-chain cryptographic system.
- Data immutability: All critical data (validated datasets, model weights, validated inferences) is stored immutably on-chain. Once recorded, this data cannot be modified, ensuring its integrity and protection against any attempts at tampering.
- Protection against malicious behavior: The PoI and PoC consensus model prevents nodes from submitting malicious data or inferences. Nodes attempting to manipulate the system are quickly identified through decentralized validation mechanisms and can be excluded or penalized.
- Process auditability: The network ensures that all transactions and operations are traceable and auditable. Every inference, adjustment, or dataset submission is associated with a verifiable history, allowing network participants to verify the legitimacy of the actions taken.
Performance Optimization and Distributed Computing
To ensure the network’s scalability, we have implemented a distributed computing architecture, which allows each node to contribute to model training and inference. This approach ensures that the network can grow exponentially while maintaining optimal performance.
- Distributed computing via PoI nodes: Training and inference tasks are distributed among PoI nodes, enabling the processing of large volumes of data without overloading a single node. This approach distributes the workload equitably and ensures high efficiency in data processing.
- Intermittent blocks to minimize on-chain overload: By using intermittent blocks, the network can integrate only the critical data necessary for the model’s operation. This minimizes on-chain resource consumption while allowing for efficient management of parameters and inference results.
Scalability and Resource Management
The modular design of the infrastructure allows the network to scale as new nodes join the system. Whether managing an increasing number of datasets, performing more inferences, or meeting greater demand for AI services, the architecture is designed to adapt to changing needs.
- Horizontal scalability: The network can grow by simply adding more PoI or PoC nodes, allowing for balanced workload distribution. The more nodes there are, the more powerful and responsive the network becomes.
- Flexible resource management: Staking and reward distribution mechanisms dynamically adjust node contributions based on the network’s needs. This ensures optimized resource usage and automatic adaptation to the workload.
Conclusion: A Vision for the Future of Decentralized AI 
The project we propose represents a significant step toward a decentralized, accessible, and democratized artificial intelligence. By relying on innovative consensus mechanisms like Proof of Inference (PoI) and Proof of Contribution (PoC), we are creating an open infrastructure where each participant can play an essential role in training and inference for LLM models.
The use of JamChain and on-chain technologies ensures not only maximum security and complete transparency, but also a circular economy powered by the DOT token. Every interaction with the AI model strengthens the network, every contribution is rewarded, and users can access AI services in an equitable and inclusive manner.
By offering decentralized governance, where each participant can influence the model’s future, and enabling exponential scalability through a distributed computing architecture, we are laying the foundation for a system that is not only resilient, but also capable of growing sustainably while adhering to the fundamental principles of decentralization.
Artificial intelligence should not be confined to large corporations or centralized platforms. With this project, we are taking a step toward open AI, where innovation is the result of global collaboration and the benefits are shared fairly among all contributors. By creating a decentralized AI infrastructure, we offer users, businesses, and developers the opportunity to actively participate in building the future of AI in a responsible and transparent manner.
In conclusion, our project’s vision is not only a solution to the current issues of AI centralization but a technological revolution that will allow everyone to have an impact on the development of tomorrow’s AI models. With a solid infrastructure, a sustainable economy, and inclusive governance, we believe this project has the potential to transform the AI landscape for years to come.

This concept is truly an idea I came up with through brainstorming with AI, resulting in a technically advanced approach that could be viable. The core idea here is that such an initiative is, in my opinion, not only obvious but necessary for everyone. It addresses the growing need for decentralization and control over the global dataset with a worldwide AI. This vision is ambitious, but let’s be clear—it is not unrealistic. At present, we are undeniably limited by the power and architecture provided by existing blockchain infrastructures. I’m open to discussions, and while my previous post is somewhat lengthy, for those who want to dig deeper, I believe this is something we should truly consider and reflect upon.