Data, the lifeblood of any worthwhile endeavor, is the central piece in solving the great puzzles of our time. It is the heart of progress and the ultimate arbiter of trust - to us it is the key to answering the question of “Why should I build on Polkadot?”. Understanding the data is paramount to harnessing Polkadot’s full potential as well as making that potential evident to external observers.
Parity data team
Our newly formed data team within Parity embarked on a quest to build a data warehouse that is currently serving Parity in the mission of decoding Polkadot’s block data as well as Polkadot’s ecosystem data and translating both into valuable community insights. Our main focus so far was covering Parity’s internal data needs but we’ve decided to progressively open up and sharing about our initiatives and what we’ve learned.
In this technical post we’ll share about what this data platform is made of and the key metrics surrounding it. We’re sharing this as a step towards contributing to what we like to refer to as the “Polkadot Data Alliance”.
This is brought to you by @pavla, @olliecorbs, @wsteves, @hakmark, myself & team.
Why did we build this?
There are many reasons why we built this and why it’s useful, the first one being the lack of standardized metrics and definitions for Polkadot and their representation on data explorer tools like Dune or Nansen.
The frequent reasons why Polkadot wasn’t being represented is that it’s a complex ecosystem and the operations required to get all the data reliably is a very tedious task.
There was a very long lead time to answer basic questions on the ecosystem.
It doesn’t have to be like this anymore.
While there are already many indexers (Subscan, Subsquid, Subquery, Sub.id, …) there is a need for a sort of database for all of the ecosystem, where it’s possible to run queries on a single chain or multiple chains at the same time and where data analysts can just use lightly pre-processed data without spending time fetching the data themselves.
A sort of abstraction layer for the community to collaborate on definitions and insights (à la Dune) using modern data engineering practices to get things like:
- Number of runtime upgrades across all chains
- Average block time in the past week for chains A, B, C
and more…
We’ve built our Platform on top of GCP (Google Cloud Platform) with the phenomenal support of our Infrastructure & DevOps team (thanks @erin & @pierre.besson).
The platform: Dotlake
In a nutshell, we’ve built a data platform to store all the blocks, events, extrinsic and more for all the chains in the Polkadot ecosystem. The platform is built in such a way that it is both scalable and cost efficient with the ambition of covering all the chains.
We’ve decided to leverage a lot of already existing technologies - on the shoulders of giants so to speak. The architecture is quite simple and focuses on low ops, meaning running as little services ourselves as possible:
- Terraform: orchestrating cloud resources
- Substrate Sidecar maintained by our Delivery Services team (thanks @gautam & @IkerParity & Tarik)
- Rust & Python
- GCP services
- Cloud Storage (backup & persistence)
- BigQuery for querying & analysis
- Cloud Run & Jobs: Sidecar API service & cron job runners
- Workflows & functions to tie it all together
How it looks like, on a high level for a single chain:

After this is setup, all what’s left to do is iterate from block number N to block number M and store the raw result, containing all the data we need as JSON in Google Cloud Storage. This provides us with a convenient abstraction as well as a documented data model that has been reviewed and implemented by our Delivery Services team. Besides, this way we don’t reinvent the wheel with a custom block parsing strategy that might be prone to errors (unknown unknowns). For now we only get blocks, but the same works for traces and other data points provided by Sidecar too.
This technical decision has been instrumental in getting us where we are today, at a point where we have a better grasp on chain data based on open source tools.
The same approach also works for an archive node in which case we loop bigger block ranges under sustained load for a short period of time. The biggest selling point of this solution is that by running the Substrate sidecar API in a service called Cloud Run, we can split the traffic towards multiple different archive nodes using revisions. This means, we can create N Cloud Run services for one chain, each connected to a different archive node and split traffic between the ingest service and Cloud Run, hence speeding up the ingest by N, regardless of any optimizations to ws-max-connections or runtime-cache-size without having to manage or maintain single servers. This is important for chains with millions of blocks and/or chains where archive nodes are not available in the same region.
Taking both these things into consideration, the full architecture can be set up in a way where it works like a clock, on a schedule and without manual intervention:
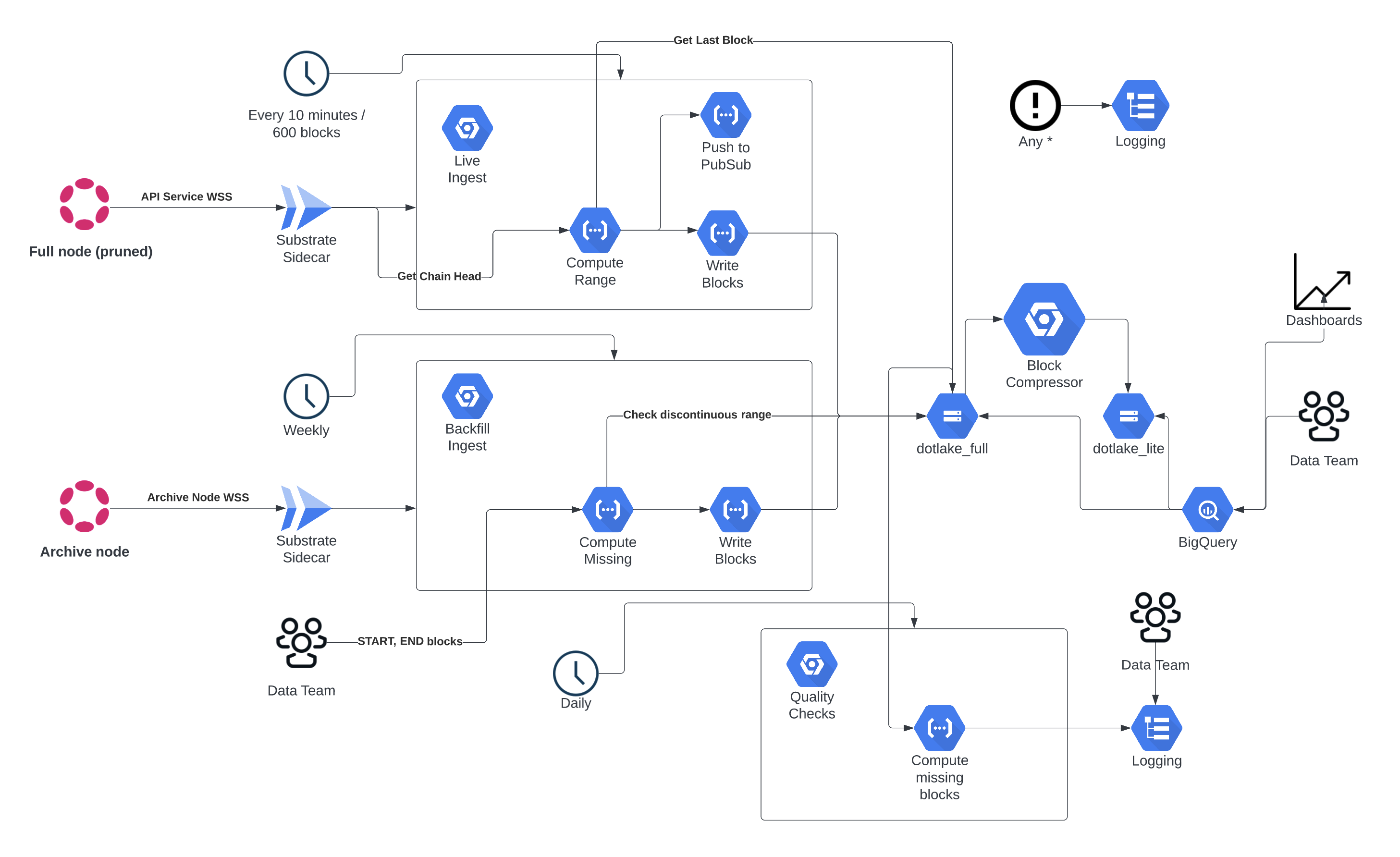
One important part of this graph is the component which we call Block Compressor. It’s essentially some piece of code which allows us to run some optimizations and reduce the amount of data that is useful for analytical purposes.
The block compressor compacts the JSON records returned by the Sidecar and drops the following fields by setting their data value to “SKIP”:
paraInclusion.CandidateIncludedparaInclusion.CandidateBackedparachainSystem.setValidationData
Doing so allows us to massively reduce the size of the blocks. This adds up the more blocks we include in the compression as they end up stored in 1 avro file. For instance, given 5 raw JSON blocks returned by the sidecar we reduce the size, from 635 KB to 14 KB which directly translates into cost savings in terms of BigQuery storage as well as very performant query times on complete historical blocks. In this “lite” format, the complete data for the Polkadot relay chain can be compressed down to 30 GB and made available as SQLite/DucksDB database for local analytics - for example.
Of course the above can be configured to run as docker-compose setup for a single chain and run locally. Given the same data model, we can collaborate on definitions, ie how to query the data and how to display it in interactive visualizations. Some simple examples we’ve developped to iterally and figuratively connect the “DOTs”:
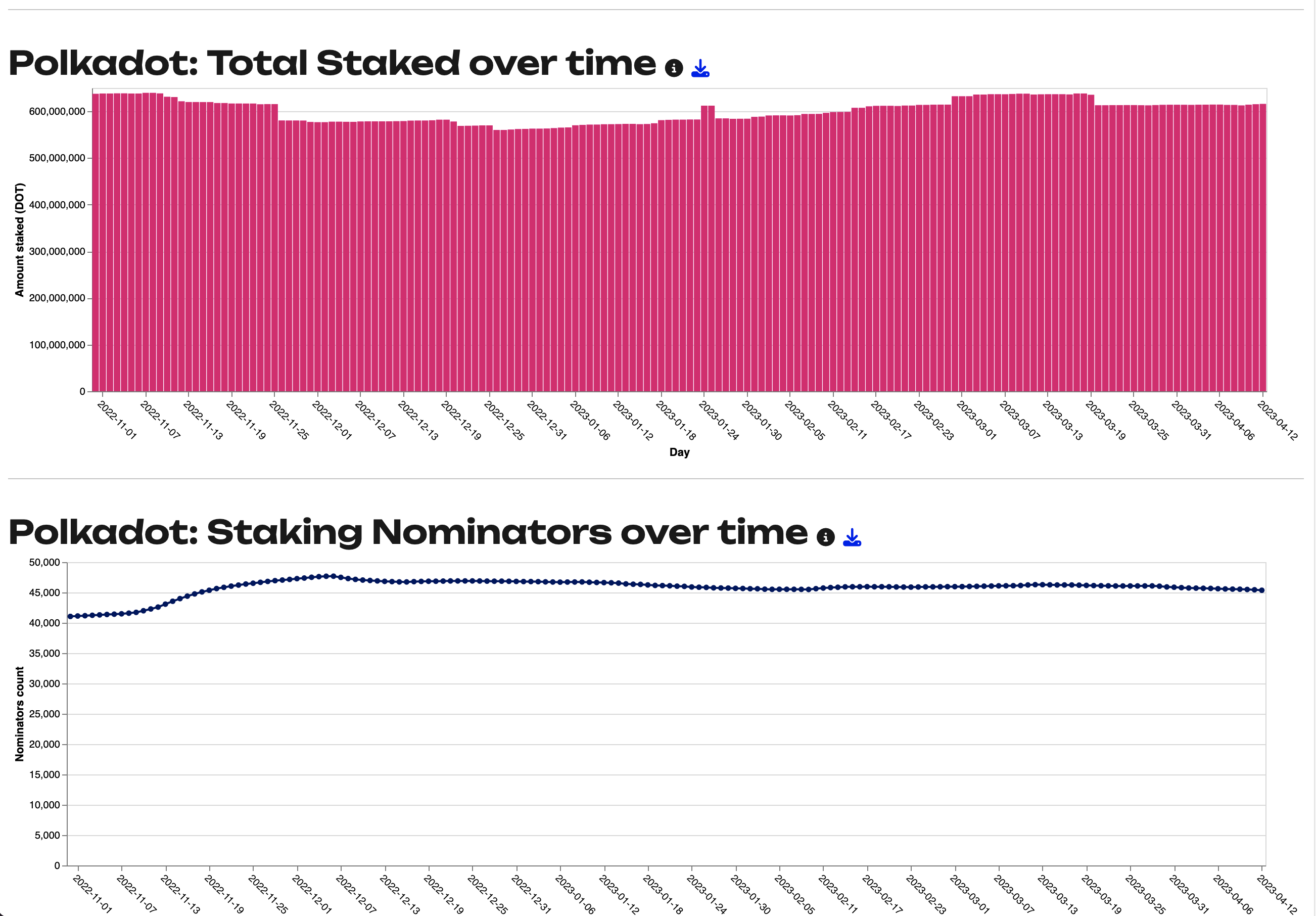
Polkadot & Kusama Block time
Courtesy of @OliverTY


Governance

Auctions

Some example queries
Not only do our data analyst know how to drop bars and normalize data, they’re working very hard in decoding the data and providing a standardized set of definitions for the Polkadot ecosystem. Some examples:
# Daily Active Addresses for Polkadot Relay & Parachains
WITH
successful_extrinsics AS (
SELECT
number AS block_number,
TIMESTAMP_MILLIS(timestamp) AS block_timestamp,
chain,
authorId,
relay_chain,
ex.success,
ex.signature.signer.id AS address
FROM
`dotlake_lite.blocks_polkadot_*`,UNNEST(extrinsics) ex,UNNEST(events) ev
WHERE ex.signature.signer.id IS NOT NULL AND ex.success = TRUE ),
daily_active_addresses AS (
SELECT
DATE(block_timestamp) AS date,
chain,
relay_chain,
"Number of successful extrinsic signers" AS metric_value,
COUNT (DISTINCT address) AS number_of_addresses,
FROM successful_extrinsics s
GROUP BY date, chain,relay_chain
ORDER BY DATE)
/*---------------------------->*/
SELECT * FROM daily_active_addresses
# 2023 Polkadot Relay DOT Transfers by Originating Extrinsic
WITH balances_transfers AS (
SELECT
number AS block_number,
TIMESTAMP_MILLIS(timestamp) AS block_timestamp,
chain,
authorId,
relay_chain,
ex.success,
ex.hash AS ex_hash,
ex.method.pallet AS extrinsics_pallet,
ex.method.method AS extrinsics_method,
ev.method.pallet AS events_pallet,
ev.method.method AS events_method,
STRING(PARSE_JSON(ev.data)[0]) AS sender,
STRING(PARSE_JSON(ev.data)[1]) AS receiver
FROM `dotlake_lite.blocks_polkadot_polkadot`,UNNEST(extrinsics) ex, UNNEST(events) ev
WHERE
ex.success = TRUE AND ev.method.method = "Transfer"
AND ev.method.pallet = "balances" AND ex.signature.signer.id IS NOT NULL )
/*----------------------*/
SELECT
extrinsics_pallet,extrinsics_method,COUNT(*) AS number_of_transfer_events
FROM balances_transfers
WHERE DATE(block_timestamp) > "2022-12-31"
GROUP BY extrinsics_pallet,extrinsics_method
ORDER BY number_of_transfer_events DESC;
Resulting in:

As you see, leaving the data untouched and parsing it using SQL afterwards, provides a lot of benefits: less code and more flexibility. BigQuery in SQL supports something called UDF (user defined functions) which can augment the capabilities of the SQL queries. As a community, we can work on this layer together and provide the necessary definitions and build new tools such as views on top of the data (transfers, XCM, treasury activity, …).
As well as getting raw block data, we also have storage function results that we store using Cloud Run Jobs (not Sidecar). You can find an example of this on our prototype public data dashboards.
Anyone can run this, reproduce the data and build up a dataset that is similar. The current data platform, runs at a cost of roughly 150£/day for 30 fully ingested Polkadot, Kusama and solo chains.
How can you access data today?
Our goal is not to keep this to ourselves. With posts like these we hope to share and build with the ecosystem. One team in the ecosystem is building a similar data warehouse and is actively working into getting Polkadot data into a BigQuery dataset available to anyone. This team is Colorful Notion (Polkaholic), represented by @sourabhniyogi and @mkchungs.
You can access the data yourself, today, in BigQuery following this guide: substrate-etl. We’re working closely with Colorfoul Notion and Google to get this data into blockchain-etl, which would make this the reference Polkadot dataset available to anyone, just like Bitcoin and Ethereum data is available as a public dataset within BigQuery.
Our goal with this collaboration is to make sure we democratize Polkadot data and not lock it in.
This initiative is linked to a WIP bounty, if you’re interested in participating, reach out to @pavla or myself. We’ll followup to this post once we have more details. We’ll make sure both these datasets will be available to the community going forward.
We’re also very closely working with SubWallet @djhatrang, TokenTerminal, Polkalytics (@alice_und_bob) and many other teams to make sure the data is available and verified/validated as well as efforts not always restarted from scratch. We’ll share about this a separate forum post as I’m starting to think this post is getting very long.
Your input
We’d love to hear what you think and if you have ideas what we could add or try out with this data as well as a pragmatic way of open sourcing this work and working more with data. One concrete way we identified would also be to contribute to Sidecar and leverage that phenomenal resource for anyone that wants to get data without writing too much code.
If you’re interested in creating infographics, interactive data visualizations, getting samples of the data or have any idea how we could make this better, reach out or create a new thread and tag anyone from the data team.
We’re also planning quite a few talks at Polkadot Decoded, you can come join the data telegram group that @dataPhysicist from Apexti created over here: Telegram: Join Group Chat
Conclusion
Ensuring accurate and comprehensive representation of the Polkadot Ecosystem is crucial to its success and growth. Representation, however, isn’t an automatic process—it needs to be nudged and supported. Data is the indispensable tool to achieve this within the Polkadot ecosystem. By harnessing the power of data, we can gain insights into network patterns, detect inefficiencies, and unveil opportunities for improvement. A clear grasp of data is vital for the Polkadot ecosystem to thrive, adapt, and foster a more inclusive environment that truly reflects the ever-evolving landscape of the blockchain and cryptocurrency world.
Now, with our trusty data warehouse as well as Colourful Notion’s substrate-etl dataset in place, we’ve given Polkadot an invaluable resource to understand what is going on. Our team’s efforts are paying off, and as the heart of science beats within our newfound data hub, we’re better equipped to navigate the intricate labyrinth of the Polkadot ecosystem.
With data as our guiding light, we’ll continue exploring the ever-evolving landscape of web3, one byte and one block at a time. ![]()