A technical write-up/devlog of the Cybergov system, a system used for automated voting on Polkadot & Kusama governance referendums. Initiating idea here: Decentralized Voices Cohort 5 - Light track - Karim/Cybergov.
Since then, MAGI-V0 got approved to be a DV-Guardian ![]() and as part of that, code, research and data will be made available for free to the community.
and as part of that, code, research and data will be made available for free to the community.
Why current strands of AI shouldn’t govern alone, but can help
Large language models are used everywhere, whether for generating code or writing blog posts, they are now considered as essential by many. While these systems are statistical next token predictors, with the right approach and an understanding of this limitation, their benefits usually outweigh their downsides. What is sure though, is that the quantitative output generated by a single person is not bounded by their personal time, but rather by how many LLM APIs they can successfully orchestrate.
Initiatives like reducing the amount of concurrent proposals on Polkadot are a consequence of governance overload, exacerbated by the ease and accessibility of creating a Polkadot proposal when leveraging an LLM. Naturally, the question was raised whether these systems would be capable of identifying an optimal path in the face of a massive amount of information: Polkadot treasury proposals are a great fit for this. LLMs could have a first pass on the proposals and evaluate it as if they were a member of the Polkadot DAO with different interests and priors. This first pass would be of course mechanical in nature, but the assumption is that their decision would be at least better than a coin toss. That is, if a single model has a probability p > 0.5 of reaching a sound judgement, then by combining the independent evaluations of three such models and aggregating their votes, we significantly increase the likelihood of landing on the correct outcome. The system would behave like a small jury, where the collective wisdom could outperform the accuracy of any single participant. Ideally, and on AVERAGE, the hope is that this system would yield good results, but the expectations for the V0 are bounded despite the public excitement.
Note: it is fair to say that the current iteration based on first generation LLMs is a “proposal evaluator” (ie: does this proposal look good) rather than a “proposal discriminator” (ie: does this proposal have a chance of actually delivering and doing so well)
The idea stemmed from a small post on X, that garnered a lot of attention and motivated me to implement this. Incidentally, the new Web3Foundation delegation program was renewing at the same time, so it was a great opportunity to also apply and try things out. I dubbed this system Cybergov because I think naming things is 50% of the job ![]()
Set and forget governance
While working on Cybergov I had one objective: close to zero daily maintenance. The project is just me and the whole point is to make sure the system is verifiably fully autonomous in its decision making. That’s the dream right, have machines do the heavy lifting while we spend precious human time on human things.
So I designed this system in a way that I don’t need to do anything, or very little, and that if there is a failure, the path to a fix is straightforward like just re-running a self-healing (idempotent) script. This meant making some conscious choices about what’s in scope and what isn’t in scope, but some assumptions and constraints first:
- Given that governance voting isn’t time sensitive, it is fine if the system operates on a schedule, meaning I do not need to constantly listen to a chain and check for new proposals on every new block. Polling in relatively long intervals is sufficient. Is there a new proposal? If not, just wait. Designing a system for polling is much, much easier than real-time listening and the failure modes are also simpler.
- Even once there is a new proposal, there is no rush. We should give the proposer some time to submit and finalize the information in the proposal and check in again later.
- The system should work for Polkadot, Kusama and Paseo independently. The latter is more to incentivize playing with the system without having to spend anything.
- A migration from one chain to another will happen during the operation of the system.
- Delegates have to publish a rationale for their vote.
- The temporal cognitive load should be low, meaning no Kubernetes and no magic stuff that I need to remember after a full day of meetings.
- The system should be transparent and verifiable. No tricks.
- Should cost peanuts, so just potato VMs and industrial glue.
- It should be possible to re-run every single step independently from another
What became immediately clear is that I will need to write some orchestration and some logic to make sure that if a task for a specific proposal fails, it is retried with some specific rules. Another thing that was clear is that there will be a lot going on at the same time, so it’s important to keep things straightforward and keep only what is absolutely necessary.
The outcome we look for in the end is the submission of a vote on-chain, which means a lot of care needs to be taken along the way. Instead of reinventing this orchestration logic from scratch and baking it into my code, I just decided to leverage an external workflow engine/orchestrator. There are many out there but to keep it simple I went with a self hosted Prefect instance. You can think of orchestrators just like managers, telling programs what to do, checking on the results and keeping an overview of the bigger picture.
The setup is like so:
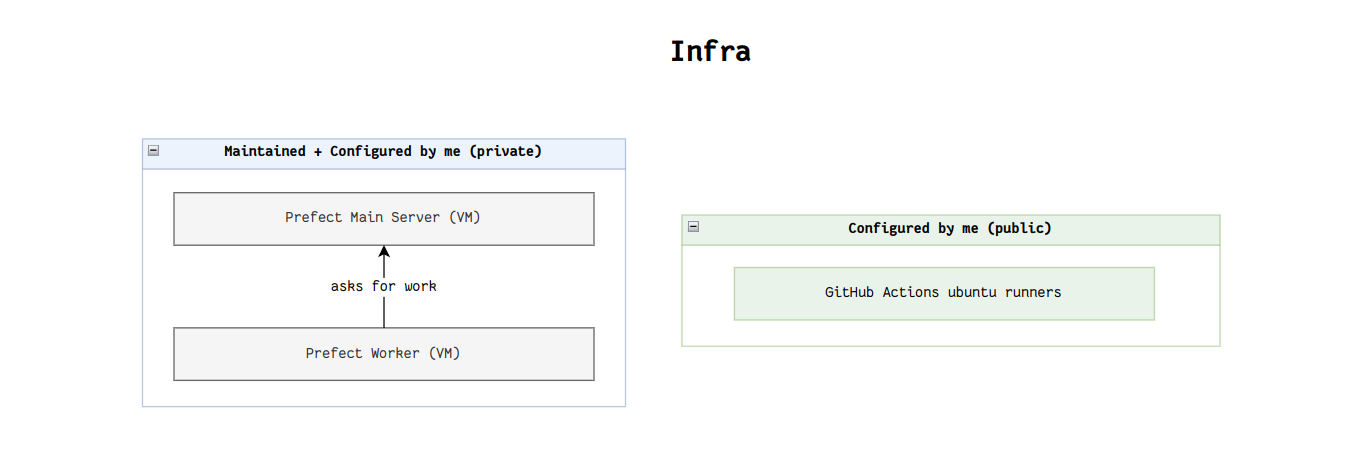
- VM A hosts the Prefect Server, this machine sends orders and tracks execution of stuff, much like a soldier ant.
- VM B is connected to the Prefect Server as a worker-pool: this machine is the worker that executes the tasks, much like a worker ant.
- Most tasks will run on VM B, apart from the inference (calling the LLMs)
- GitHub runners: a public, verifiable space that will host the inference.
This provides the basis upon which we’ll run things.
Governance task orchestration
At first I considered the hosted cloud option for Prefect, but it’s expensive for what I’ve calculated would be “hobby” use. Just a few tasks per day at worst. Prefect allows me to do cool things like task dependencies, tasks scheduling other tasks, retries, logging, and a neat dashboard overview of everything that is going on. It is minimally invasive, some function decorators on my Python methods and I’m in business. It also handles secret variables without having to be an expert in IAM roles or whatever.
The main tasks that are crucial for cybergov are split in the following logical units:
- For each network and appropriate delegation track:
- Detect new proposals
- Collect & store the data
- Clean & “augment” the data and add further information to it (limit the size of proposals)
- Run the LLMs on the data & store the vote
- Submit the vote on-chain
- Submit a rationale in public
It should also be possible to add additional tasks in between without having to rewrite the system (append only, ideally). This is to leave the room for a V1 should there be one. Like maybe we want to introduce a vector store of past proposals and do retrieval of augmented generation, by adding meta-information on past proposals and their performance, or, we can add further generation loops on the proposal data itself. @tom.stakeplus and I are exploring this independently here and I believe we could generate a valuable resource for the community, like additional processing tools for proposals.
Data is where 90% of the work lives
Of course the invisible burden is always properly scraping, cleaning, processing and versioning proposal data. Most of the time for this project went into this, how to get and properly store the data in a way that it makes sense, the rest was really just writing down some code to do the stuff I want. If you ever worked with human generated data, it is messy, it is not standardized and it is very difficult to make sense of. You don’t get types or metadata, and we’re not talking about a set of cron jobs to run on a raspberry pi here. Luckily, here we can also leverage LLMs to do some heavy lifting.
What data are we storing?
Proposal data (contents & on-chain characteristics), yeah sure, but do we want to scrape the linked documents in the proposals? If yes, we just increased the complexity of the project 10 fold given that external links can change and are very time intensive to reliably automate. And the juice isn’t worth the squeeze. Based on historical data, there are a LOT of different options people use to pitch their proposals. From IPFS (mostly 404ing) to Google Docs (no more access) and MS Paint artworks there’s a lot that’s been tried out in the past. I believe nothing beats text in the end, especially if it’s versioned and stored in a way that it can be retrieved when we’re all grey and old. As an ecosystem we still haven’t completely solved the altering of proposals after they are submitted because we continue to leverage non Web3 tools to do our Web3 governance.
If a proposal heavily relies on external links (“check the proposal in the comment section below!”) I designed the system to abstain, as whatever decision will be taken, couldn’t be taken in a way that is verifiably un-changed.
Where & how to store the data?
The different pipelines will need a way to read and write datasets. A very natural choice is to just use some random database and call it a day. But we have a problem. One of our constraints is transparency so we need a way to provide and link to singular artefacts for people to verify things. Nothing beats using files for this purpose. Using files as a source of truth also has the benefit that the archival is straightforward, versionable and portable. A natural choice then for this is using something like an S3 compatible object store. IPFS was also initially considered but introduced its own set of challenges.
How to store the data?
When storing data, the main thing one usually takes into consideration is how the data will be accessed. Our main units here are the network (polkadot, kusama, paseo) and the proposal number. We won’t query proposals by date or anything like that and the amount of data per proposal is very small, given we just take into account text. So more advanced partitioning keys are unnecessary. The jobs themselves can then use these to know where to store what. We come to the following structure:

Note: for now, the public comments will always link to the LATEST vote. A script will be developed to make sure we can point old comments to their respective vote number.
How do we serve the data?
The last piece of the puzzle is giving people access to the data because it’s why we’re storing it. It is unwise to provide public access to an S3 bucket, unless it is a growth generation trick. That’s why I’ve put a CDN in front that serves the data. Relatively straightforward.
Three minds, one vote
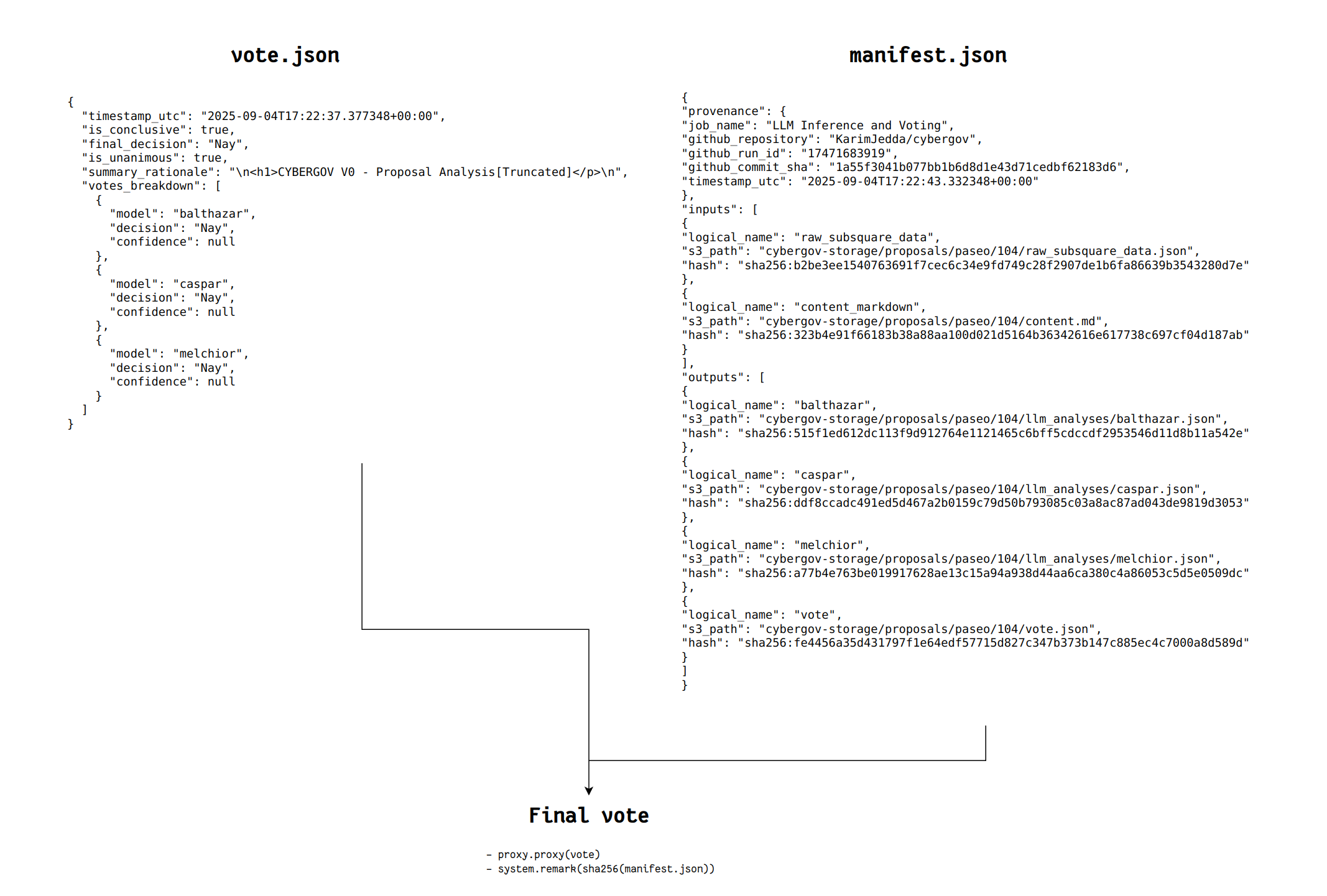
The rationale behind using 3 independent LLMs is explained in the seminal forum post where I applied to become DV. The TLDR is robustness, redundancy and sanity checks. Now, for the LLMs themselves, I cannot run these on my own servers, since it is guaranteed that some keen observers will not hesitate to go on long Twitter crusades or post anonymous comments about how this is “Karim-in-the-middle”-gov and insinuations/libel that I’m actually pulling the strings at OpenAI. Given trolls thrive in obscurity, the LLM inference runs have to be public and their inputs & outputs verifiable, this is non-negotiable. To achieve this, we do a few things:
- First, we hash the inputs and outputs of the LLMs and provide all of that in a manifest.json, that is itself hashed.
- The hash of this manifest.json is
- submitted on-chain alongside the vote as a system.remark in a utility.batch call
- explicitly written in the output of the GitHub action running, running on GitHub servers (not controlled by me)
The anatomy of how a vote is created, is roughly this:
This shifts the trust assumption around a bit:
- Can I forge the inputs of the LLMs? Yes.
- Do I have an incentive to do that? No.
- Can I forge the inputs of the LLMs without it being seen? No
- Can anyone prove independently that a specific set of files led to an executed outcome? Yes.
- What about code changes?
- The code + input & output data are versioned and pinned in the manifest.json.
These answers collectively show where we are on the trust spectrum. The system I built here is what’s called verifiable, meaning cheating is possible but verification makes it detectable. I’m providing scripts in the repo for anyone to check if things add up. To make it clear, from the time that the proposal is fetched to the time a comment is posted, there is 0 intervention on my end. Successive ids for the public GitHub action runs, would indicate that inference runs weren’t run and re-run in the hopes of achieving a target outcome.
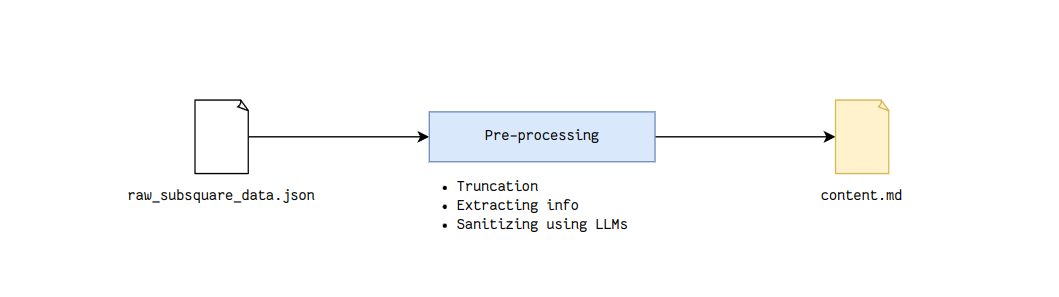
Below is an illustration of the full path of a vote. First, we fetch and augment the contents of the proposal using a neutral language model. Its instructions are just to respond to some simple questions with the proposal text provided:
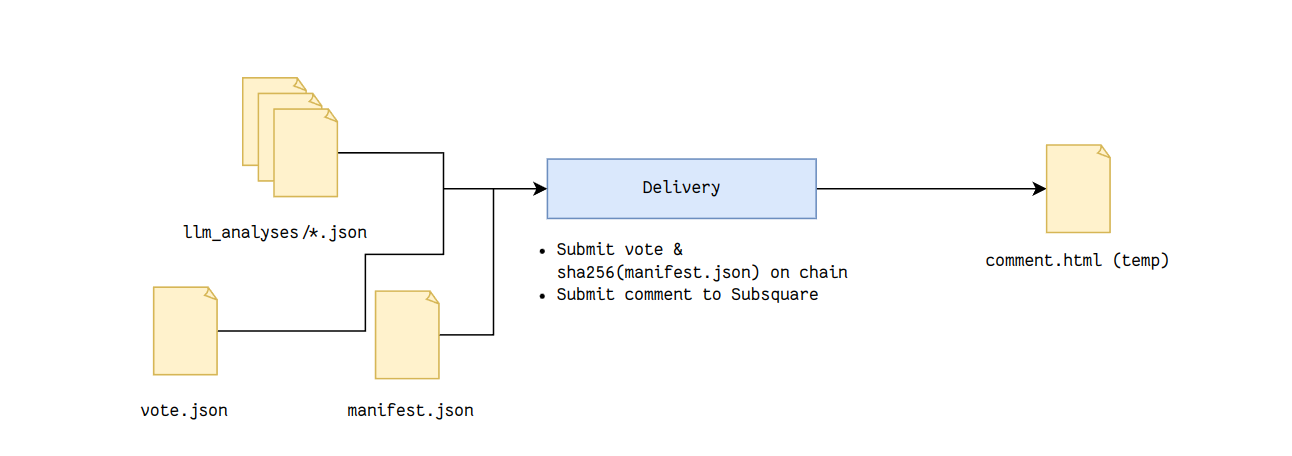
Then, what happens is the inference picks up the code from GitHub and the sanitized proposal data, and runs the inference on the public GitHub runners. These in turn generate the rationales, the manifest.json (verifiable artefact) and the final vote information:

Then, the last step is simply compiling all that information into a vote + a comment that is submitted on the respective platforms. These submissions should be signed by the keys of the accounts to prove provenance and authenticity. Nobody can tamper with the data and have it correct, the worst that can happen is that the data is no longer available, but archiving text files is straightforward.
Proxies, delegations and airgapped vaults
This project has received a delegation from the Web3Foundation. It is an honor and a privilege to be granted this responsibility which means that I can’t just generate a random key and use it in the CLI in GitHub actions and grab a mojito. It has to be secure. That is why the main account that receives the delegation is an account in an airgapped Polkadot Vault device. A secure account is generated on a separate device and has just a few calls to make. The account structure looks like so:

The accounts that will submit the vote calls will be Proxy accounts that get Governance delegation from the main account. These accounts should be treated securely, but have a different threat model and blast radius than a compromise of the main account. These proxy accounts can also independently post comments on Subsquare. In fact, Subsquare has a neat API, where I can directly submit signed payloads. They use a spec called SIMA which I invite you to read here. The terminally online cypherpunk will most certainly recognize some parallels here with how NOSTR works. Regardless, it worked great but I learned the hard way that Python httpx.post and javascript post do not work the same way at all. Yongfeng was so nice and pinged me with cool information: we can add a field to make sure the comments look like they were posted by the proxied account! Neat!
How a vote looks like on Subsquare:

Execution flow: from proposal to on-chain vote & comment
Now let’s have a look into the insides of the systems a bit more.
The dispatch is a job that runs every hour and is only responsible for polling the respective networks and scheduling scraping & augmentation tasks.
The scrape & augment is responsible for:
- Fetching & storing the proposal data from the Subsquare-API into an S3 bucket
- Pre-processing the data by generating the cleaned proposal data that the LLMs will use for voting
- Keep options open to add more pre-processing tasks
The inference task does the following:
- It triggers a GitHub runner with specific parameters: network & proposal_id
- This runs on GitHub runners & outputs the SHA256 metadata.json
- The GitHub runner executes the DSPy LLM inference logic and outputs the analysis & rationales
- It polls and waits to see if the job is successful or not, if successful, it triggers the vote task
The voting task fetches the vote result, loads the proxy accounts and submits the proxy call alongside the hashed metadata.json. It then submits all of that on-chain & schedules the commenting task. The commenting task then submits a comment on the proposal page with the required links and written rationale. The illustration below shows how the system looks from a complete view. It’s my best attempt at trying to show all the moving pieces in one image. If it isn’t clear, let me know and I will try again.
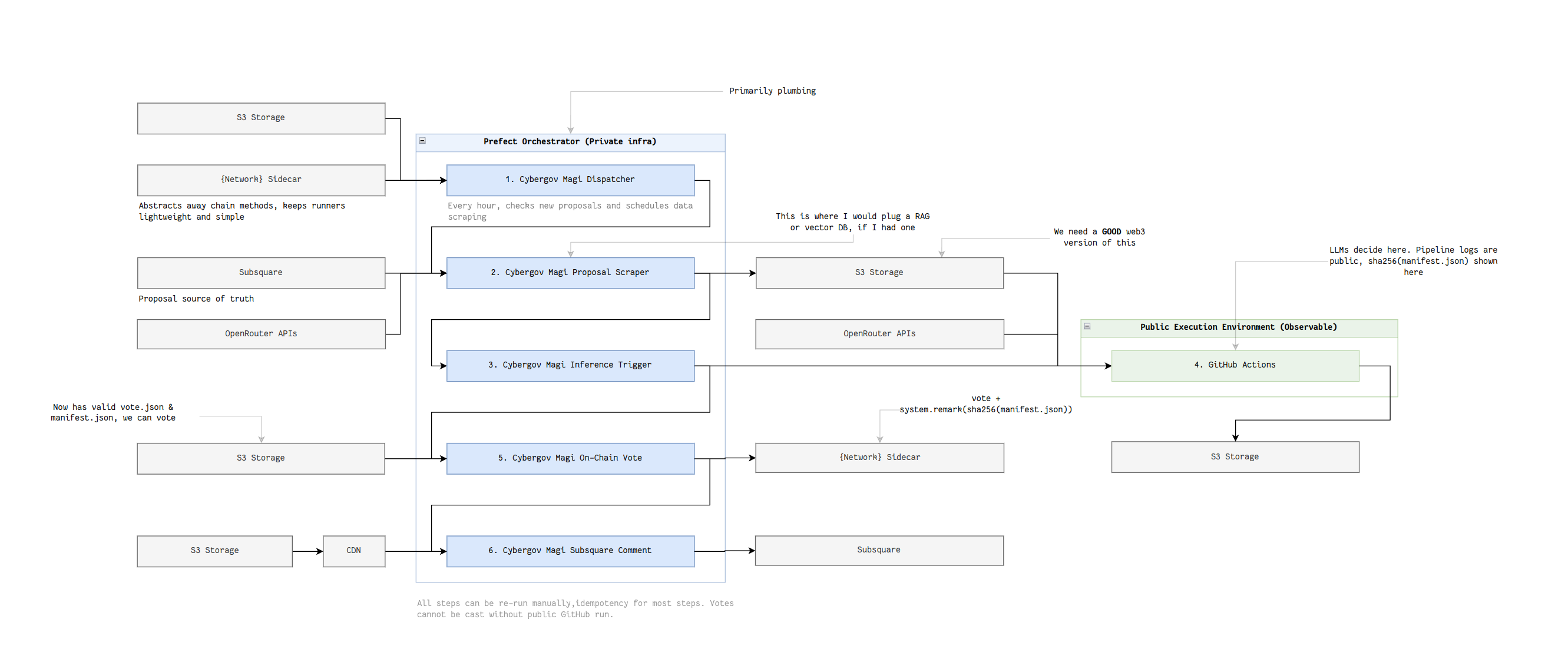
Every single step of the process is automatically tracked and stored out of the box, because we decided to use an orchestrator.
Infrastructure simplicity: Sidecar & REST
The system leverages Substrate Sidecar quite a lot, it’s lightweight, RESTful and stable. The idea here is to separate the different failure modalities and keep contexts separate. Substrate Sidecar serves as a convenient API and translation layer providing me what I need, when I need it. I do not want to keep persistent websocket connections and have to debug timeouts, side effects or issues or anything associated with that for this use case. GET for reading stuff & POST for submitting transactions are all I need, and that gives me simplicity & predictability with an offline signing / online submission model.
Next, this architecture choice proved very useful and I felt quite happy when the Paseo AHM hit during the development of the project. I had to do 0 changes to my code, the only thing I had to change was switch the Substrate Sidecar from one pointing at a Paseo Relay Chain node, to one pointing at a Paseo AssetHub node. Done. No alternative code paths to develop/remove or any version juggling to handle in my code, Substrate Sidecar wins and I believe we should double down on it by making an excellent version based off of subxt.
Aesthetics, feedback & community
I’ve quite honestly learned a lot and had heaps of fun doing this. It took around 10 - 15 hours in total to finish this, spread across multiple days. One thing’s for sure, verifiability is much harder than automation, but also much more important.
The code and architecture above is the logic, but it isn’t close to what took the most time. I spent a lot of time thinking about aesthetics and emotion. What should we name this? What should we call it? How should it look? How to explain it? And so forth. I believe feelings matter in decentralized systems and any time spent making things look good, sound good or feel good are things that compound and help the tech by appealing to users (“LLMs voting verifiably on-chain” is a unambiguous proposition). Think about a beautiful piano piece, people care less about the piano’s technical specifications than the harmony of the piece played on it. And a “MAGI system” resonates perhaps better than “3 LLMs in a trenchcoat”.

Governance is hard, and leaves clear marks on the ecosystem and the people in it. Although LLMs tend to prefer being agreeable and complacent (a very dangerous characteristic reinforcing cognitive dissonance, currently under study), the LLMs that vote are specifically instructed to not “behave” like that (for lack of better words). This will definitely be upsetting to some when an AYE vote is cast on a proposal they do not like, or a NAY is cast on theirs. So given that mistakes might happen, I’ve set up a GitHub issue tracker that will be available to request a re-vote, also in public. Questions will mainly be responded to there, in the open. I also accept PRs for prompt tweaks. If we can collectively improve those, we all win. Ideas are also very welcome.
This system is complex, it leverages proxy accounts, delegations, on-chain votes, cryptographic hashes, some private/public infrastructure and that’s a good technical feat. But will the votes themselves be good? Or entertaining? Or interesting? I guess we are going to see and that’s what is more interesting to me. I suspect the first votes to be pretty basic, but with further tweaks to the system, we’ll make it much much better. The Subsquare team made a phenomenal dashboard where you can follow DV votes: https://polkadot.subsquare.io/referenda/dv
I tried to submit a proposal for building a forest on the moon on Paseo, but the system cast an unanimous NAY. The system doesn’t trust me either.
Toward trustless AI governance
As these LLMs improve independently, we now have a system where we can plug any of the new LLMs without changing the code or logic substantially. The v0 is a working prototype with principles of trust-minimization baked in. The public GitHub runners, along with the hashing of the inputs & outputs makes things verifiable. Given a submitted vote with a hash, it’s possible to know which manifest was used to vote but also which GitHub pipeline (and thus, inputs!) led to that vote. We can make subsequent versions trustless and I’m exploring that. But we need some primitives first: what is the S3 of Web3? What is a CDN in Web3? How can I get a decentralized orchestrator? How can I do LLM inference on decentralized & verifiable infrastructure? A lot of ambitious things to build! ![]()
The code is free software available here: GitHub - KarimJedda/cybergov: LLMs participating in Polkadot governance decisions . The documentation for how to run this yourself is a WIP, but any qualified engineer could make it run in ~ 3 hours. PRs are very welcome! One thing is for sure, I completely underestimated the effort it required to build this from scratch. But I’m glad it’s done and I can now work on the next idea I have. I hope my blog/forum post is helpful to you if you want to build a similar thing!
The initial reception of the system was absolutely overwhelming and I’m absolutely thrilled to see the interest for this, and that motivates me to keep going. The first vote was already cast, setting what I like to think of as a public milestone:
I would like to thank @wliyongfeng , @kukabi for the technical support and help, @0xTaylor & @tom.stakeplus for the ideas and support throughout, the Web3 Foundation, specifically @Zendetta and @bill_w3f who are running a great DV program, but also the community for motivating me to do this. ![]()
Tech used: py-polkadot-sdk (formerly substrate-interface), Prefect, DSPy, S3, Python, Subsquare-API, Substrate Sidecar, Polkadot Vault.