Lately, you may have noticed new jobs in CI with “subsystem-benchmark” in the name. You may also be wondering why they often fail. Here I’ll explain what this is all about.
Motivation
The Parachains Core team builds and maintains the protocols that sit at the base layer of parachain consensus. In a node part, the consensus is spread over many modules, which we call subsystems. Each subsystem is responsible for a small piece of logic, such as validating parachain blocks or reconstructing availability pieces. Despite the distribution of logic, most of the load and performance problems are localized in just a few subsystems, such as availability-recovery, approval-voting, or statement-distribution.
To test the most loaded subsystems, we had to run entire large testnets. Setting them up and managing the amount of data they produce is very expensive, hard to orchestrate, and it’s a huge development time sink.
Therefore, our goal was to measure the subsystem CPU and network usage with different network parameters without running the actual network. The benchmarking tool was introduced in #2528. It now consists of three parts:
- a framework,
- a CLI tool,
- CI benchmarks.
Framework
The framework is a core component. We set up a test environment with real and mocked subsystems, emulate peers in the network. The test configuration depends on such parameters we use in a real network, such as number of cores and validators or PoV sizes. We describe a test scenario, setting up block candidates, messages, etc. Then we run the scenario over a number of blocks and collect CPU and network usage.
For CPU usage we utilize async-futures polling times, so we have a distribution of usage per subsystem and its individual tasks.
Currently, implemented benchmarks for:
- availability-recovery.
- availability-distribution. bitfield-distribution and availability-store involved.
- approval-voting. approval-distribution involved.

Run of DataAvailabilityWrite benchmark #2970. The benchmark measures the network and cpu usage of availability-distribution, biftield-distribution and availability-store subsystems from the perspective of a validator node during the backing process.
CLI tool
The CLI tool runs benchmarks whose configurations are described in .yaml files. So we can use the same test scenario to describe different test cases. For example, for the approval-checking we have:
- Best case throughput: we use only the minimum required tranche to collect the required approvals.
- Maximum throughput: we send all the tranches for each block.
- Behavior in case of no-shows: we set a maximum number of no-shows per candidate.
We designed the CLI tool to run benchmarks on a developer’s machine. While working on a fix or enhancement, the developer may need more than just a few CPU or network usage numbers. So we added a support for some profiling tools:
- Basic subsystem metrics: we run Prometheus along with our tests so we can look at common subsystem metrics like time to recover a PoV or a chunk request duration.
- CPU flamegraphs: it’s possible to run Pyroscope to profile our CPU usage.
- Cache misses: we use Cachegrind, which has many drawbacks, but unlike perf, it can be run in a virtual machine.
If you are interested in setting up and running the benchmarks, you can find all the information you need in the README and sample configurations.
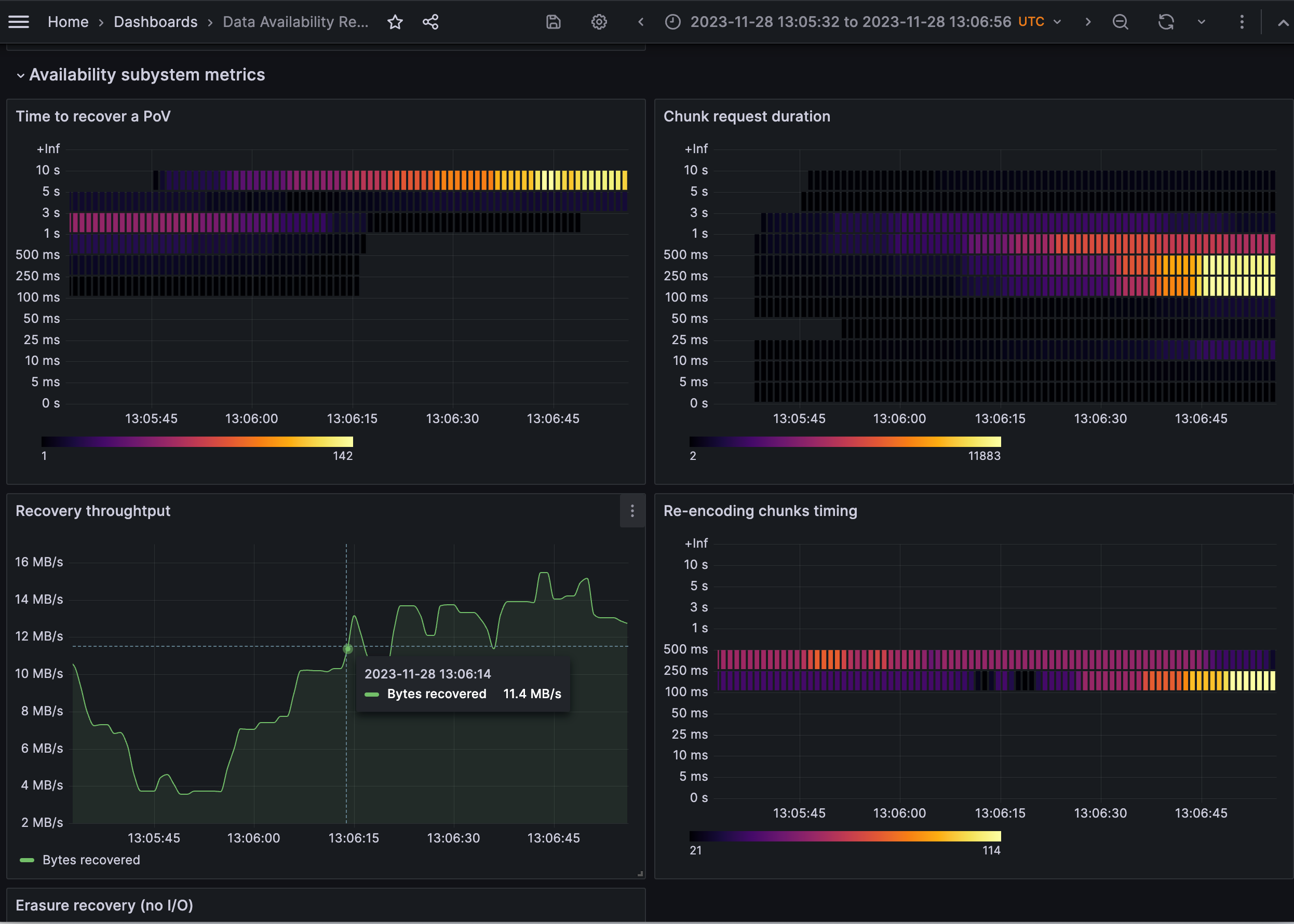
Prometheus metrics for DataAvailabilityRead #2528. For each block we send a RecoverAvailableData request for an arbitrary number of candidates and wait for the subsystem to respond to all requests before moving on to the next block.
CI Benchmarks
Subsystem benchmarks in CI is another part that is supposed to catch possible performance regressions. Each benchmark is just a function without standard bench harness that can affect the performance. In each test case, we use the parameters of Kusama network.
We run CI subsystem benchmarks for every PR but it’s allowed to fail. Currently, they are in a calibration mode and don’t stop PRs from being merged. We aim to reach such level of accuracy where results deviate from the baseline no more than by 5%. Then we’ll enable our benchmarks as a fail criteria.
Results from the master branch are stored and displayed as charts. Unlike CI jobs we can see on charts that volatile values do follow a trend. Please don’t consider current drops as a regression. We’ve only recently started CI benchmarks and are still playing around with the configuration. Live available charts you can found here:

Charts for the approval-voting regression benchmark. Values collected for the master branch. A baseline value is shown along with a ±5% threshold.
What next
We don’t expect quick results. Subsystem benchmarks can be used immediately to prove some hypotheses. For example, you can see in #2621 how the approval-voting benchmark can be used to quantify improvements from new optimisations (#1178, #1191). But our long-term goal is to collect reliable data to prevent regressions or to recognize improvements after some time.
So our current tasks are:
- Implement more benchmarks: statement-distribution is wip and dispute-coordinator is good to have.
- Stabilize the results: we want to have no more than 5% deviation from the baseline.
If you have any questions or ideas, feel free to drop me a line.